# Distributed Job Scheduler system design
Distributed Job Scheduler system design (opens new window) 를 읽고 정리한 내용입니다.
대량의 user-submitted jobs을 확장 가능하고 내결함성 있게 관리, 추적 및 실행할 수 있는 분산 작업 스케줄러를 설계합니다.
# High level system design
다음은 분산 작업 스케줄러의 고수준 시스템 설계(high level system design)입니다.
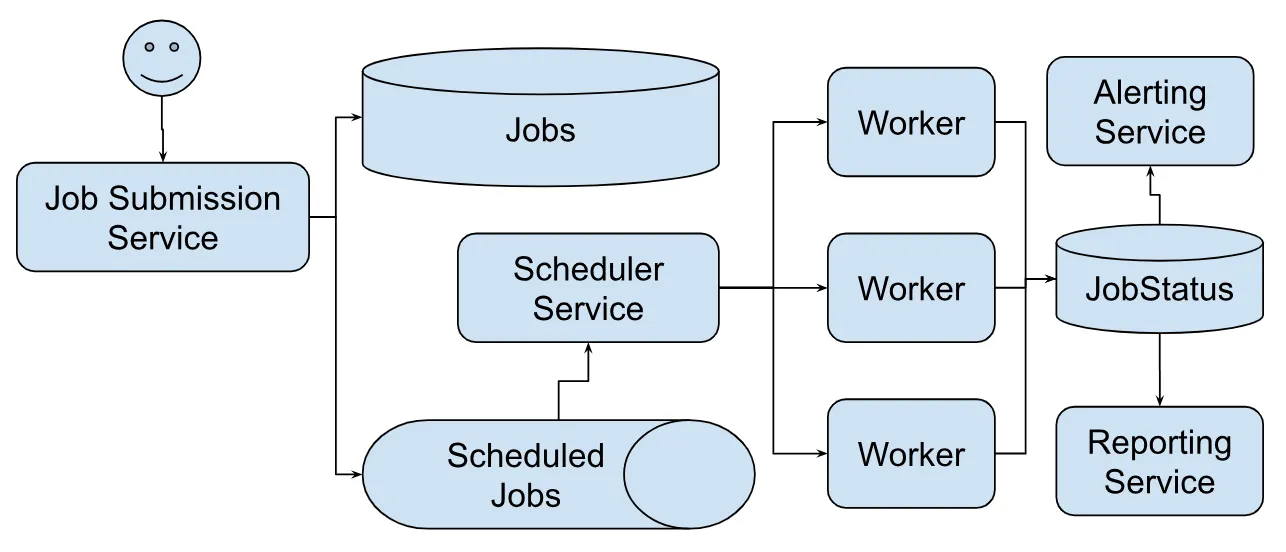
각 서비스를 자세히 살펴보겠습니다.
# Job Submission Service
Job submission service는 Jobs 테이블에 기록합니다. Jobs 테이블의 스키마는 UserId+JobId를 기본 키로, UserId를 샤드 키로 사용합니다.
샤드 키(shard key)는 분산 시스템에서 데이터를 여러 서버(샤드)에 나누어 저장할 때 데이터를 어떻게 분배할지를 결정하는 기준이 되는 키입니다. 데이터베이스가 수평적으로 확장되기 위해서는 데이터를 여러 샤드로 나누어 저장하는 것이 효율적이며, 이를 통해 시스템의 성능과 처리 용량을 높일 수 있습니다.
| UserId | JobId | IsRecurring | Interval | MaxRetry | CreateTimestamp |
|---|---|---|---|---|---|
| 1 | 1 | True | 0 */2 * * * | 3 | t1 |
| 1 | 2 | True | 0 */6 * * * | 1 | t2 |
| 1 | 3 | True | 0 0 * * * | 0 | t3 |
| 1 | 4 | False | NULL | 3 | t4 |
| 2 | 5 | False | NULL | 3 | t4 |
Job submission은 또한 작업을 분석하고 ScheduledJob 큐에 작업 주기에 따라 TTL을 설정하여 대기열에 추가합니다. ScheduledJob은 다음 스키마를 사용하여 예약된 작업을 저장하며, NextExecutionTimestamp가 샤드 키로 사용됩니다. 타임스탬프 기반 샤드 키는 대기열 시스템이 매 분마다 같은 위치에 있는 작업을 가져오도록 돕습니다.
| NextExecutionTimestamp | JobId |
|---|---|
| T1 | 1 |
| T1 | 2 |
| T1 | 3 |
# Scheduler Service
스케줄러 서비스는 작업을 실행할 때 다음 두 가지 결정을 내려야 합니다.
- 작업이 주기적(interval)인 경우, 다음 실행 시간을 계산하고 다시
ScheduledJob큐에 대기시킵니다. - 작업의 유형, 종속성 등을 분석하고 적절한 워커 노드를 찾아 작업을 실행합니다.
# Workers
작업에 따라 여러 유형의 워커를 사용할 수 있습니다.
# 멱등성 워커(Idempotent workers)
분산 시스템에서는 (재시도 등으로 인해) 중복 메시지가 워커에 전달될 수 있습니다. 따라서 워커는 멱등성(idempotency)을 유지해야 합니다. 즉, 두 워커가 동일한 작업을 병렬로 처리하더라도 서로 영향을 주지 않아야 합니다.
# 비멱등성 워커(Non idempotent workers)
일부 작업은 특성상 여러 워커가 동일한 작업을 동시에 처리하지 않도록 해야 합니다. 이 경우 워커는 외부 저장소를 참조해 작업 진행 상태를 확인하고, 처리 중인지 확인하여 필요에 따라 작업을 계속하거나 중단합니다.

# 단기 작업(Short running job)
몇 초 안에 완료할 수 있는 단기 작업은 타임아웃 내에서 대기열에 응답할 수 있습니다.
# 장기 작업(Long running job)
일부 작업은 실행에 몇 분 혹은 몇 시간 이상 걸릴 수 있습니다. 대기열 시스템은 이 정도로 오래 기다릴 수 없으므로 이벤트가 타임아웃되어 다른 워커에게 재전달될 수 있으며, 이로 인해 동일한 작업이 여러 워커에서 재처리될 수 있습니다. 장기 작업을 처리하는 여러 방법이 있으며, 작업의 특성에 따라 다릅니다.
작업 처리 페이징(Paginate the job processing)
작업 범위를 작은 청크로 나누고 페이지 방식으로 처리합니다. 이 접근 방식은 작업을 단기 작업으로 변환합니다.Checkpoint테이블을 사용해 작업 진행 상태를 확인합니다.JobId PageSize PageStart IsCompleted 1 10 20 False 2 10 0 False 3 10 100 True 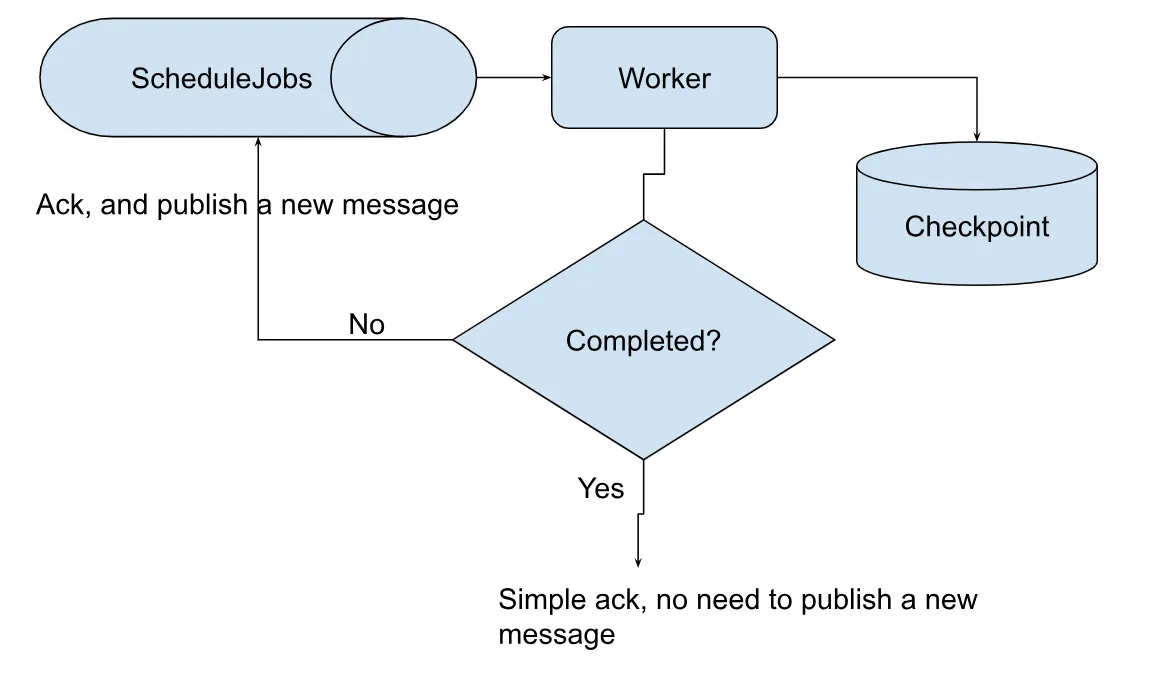
장기 실행 작업을 위한 미래 메시지 대기열 추가(Enqueue message for long future)
작업을 작은 청크로 나누기 어려운 경우JobStatus테이블을 유지하여 처리 상태를 확인합니다.JobId Status 1 INPROGRESS 2 COMPLETED
# 재시도 메커니즘(Retry mechanism)
작업의 재시도 옵션에 따라 워커 노드는 메시지를 확인하거나 확인하지 않고 재전송합니다. 재시도가 가능한 작업의 경우 실패 시 메시지를 확인하고, 메시지를 새로 발행하며 재시도를 진행합니다. 재시도가 불가능한 작업은 실패 시 메시지를 확인하지 않고 중단합니다.
# 작업 실행 이력(Task execution history)
작업 실행 완료 후 워커는 작업 실행 이력을 기록합니다. TaskExecutionHistory 스키마는 다음과 같습니다.
| JobId | StartTime | CompletedTime | Status | RetryCount |
|---|
# 보고 서비스(Reporting Service)
보고 서비스는 Jobs와 TaskExecutionHistory 테이블을 사용해 사용자별 작업 상태를 표시합니다.
# 알림 및 모니터링 서비스(Alerting and monitoring service)
작업 실패율을 모니터링 시스템에 기록하고 조건에 따라 알림 규칙을 구성할 수 있습니다.
# 스케일링 작업 스케줄러 시스템(Scale job scheduler system)
사용자와 작업의 양에 따라 각 컴포넌트를 수평으로 확장할 수 있습니다. 저장소가 적절히 분할되어 있어 수평 확장이 용이합니다.
reference: Distributed Job Scheduler system design (opens new window)