# MLOps 02: Dagster — Seamless Data Pipelines & ML Model Management for Machine Learning Engineers
MLOps 02: Dagster — Seamless Data Pipelines & ML Model Management for Machine Learning Engineers (opens new window) 를 읽고 번역한 내용입니다.
# DataOps와 MLOps의 동기
머신러닝 엔지니어링 파이프라인은 크게 세 가지 단계로 나눌 수 있습니다:
- 데이터 준비
- 모델 학습
- 모델 서비스 레이어
모델을 서비스하는 최종 단계까지 원활하게 엔드 투 엔드 데이터 파이프라인을 수행하기 위해서는 오케스트레이션 프레임워크가 필요합니다. 필요한 기능으로는 다음이 포함됩니다: 방향성 비순환 그래프(DAG), 스케줄링, 워크플로우 관리, 오류 처리와 재시도 메커니즘, 모니터링 및 로깅.
현재 다양한 오케스트레이션 프레임워크가 존재하며, 오픈 소스 솔루션부터 AWS와 Microsoft Azure와 같은 클라우드 서비스에 내장된 솔루션까지 폭넓게 제공됩니다. 가장 인기 있는 오케스트레이션 프레임워크 중 하나는 Airflow이지만, 최근 떠오르는 프레임워크인 Dagster는 데이터 파이프라인 개발에 유용하고 풍부한 사고방식을 제공합니다.
이전에는 이러한 오케스트레이션 프레임워크가 주로 작업과 운영에 집중되었습니다. 그 결과, 모델 운영과 데이터 운영은 종종 간과되었습니다. 그러나 이제 데이터베이스 내 테이블이나 머신러닝 모델처럼 관리, 모니터링, 버전 관리가 가능한 자산(asset)이라는 개념이 도입되면서, 단순히 작업과 운영에만 집중하던 것에서 데이터에도 초점을 맞출 수 있게 되었습니다.
# 데이터 파이프라인에서 Dagster 자산 구현

Dagster 자산이 데이터 파이프라인에 어떻게 구현될 수 있는지 설명하기 위해 예시로 더미 데이터 파이프라인을 살펴보겠습니다. 이 예제에서는 두 개의 상류 자산(Upstream 1과 Upstream 2)과 하나의 하류 자산(CombineAsset)이 있습니다. Dagster 자산을 import하고 @asset 데코레이터를 사용하기만 하면, 함수 이름이 자산 키가 되어 Dagster 프레임워크 내에서 관리할 수 있습니다.
Dagster를 사용하면 복잡한 데이터 파이프라인을 풍부한 시각화 및 주석 기능을 통해 쉽게 관리할 수 있으며, 기존 오케스트레이션 프레임워크 및 기술 스택과 유연하게 통합할 수 있습니다. Dagster는 경량화 되어 클라우드 네트워크의 클러스터에 배포하기 전에 개발 환경에서 쉽게 디버깅 및 테스트할 수 있습니다. 또한, Dagster 커뮤니티는 활발하게 변화하며 현대 데이터 엔지니어링 요구 사항을 지속적으로 지원하고 있습니다.
# 기존 기술 스택과 Dagster 통합
Dagster는 MLflow, Airflow 또는 DVC와 같은 데이터 버전 관리 도구를 포함한 기존 기술 스택과 쉽게 통합할 수 있습니다. 설치 후, Dagster는 이러한 기술 내에서 자산을 관리하고 구현하는 데 사용할 수 있습니다.
# 설치
pip install dagster dagit
# 자산 구현
from dagster import materialize
if __name__ == "__main__":
result = materialize(assets=[my_first_asset])
# Dagster를 활용한 효율적인 데이터 전송 및 버전 관리
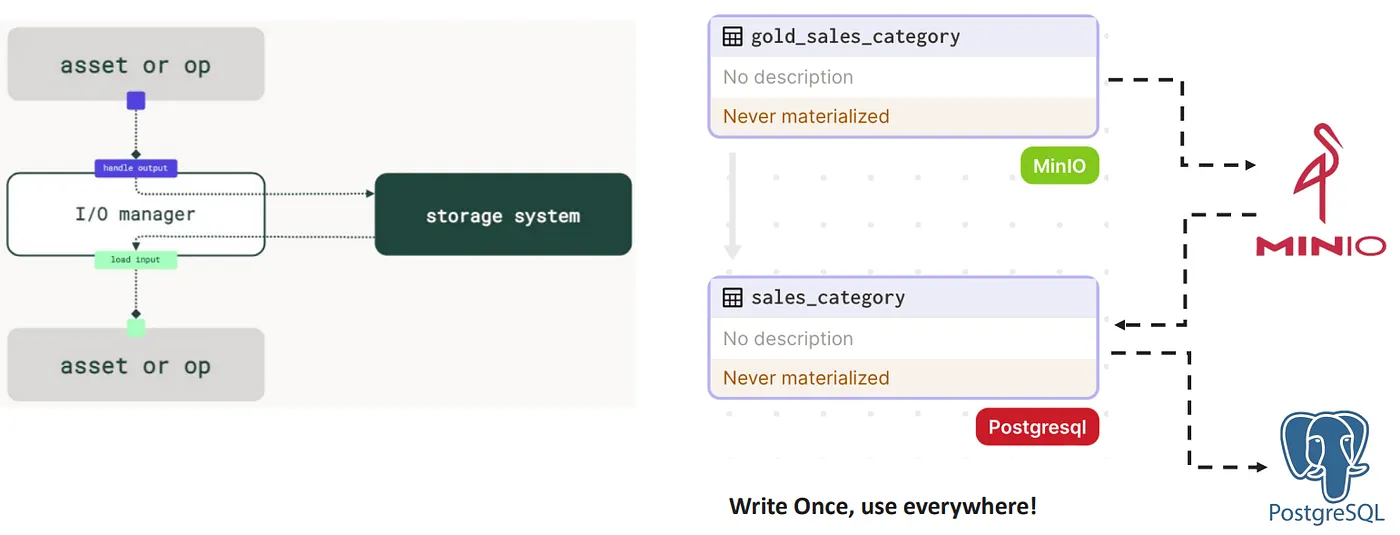
Dagster의 주요 장점 중 하나는 IOManager 개념을 통해 다양한 데이터 소스 간 데이터 전송을 간소화할 수 있다는 점입니다. 각 스토리지 유형(API, SQL 데이터베이스, 객체 스토리지 등)에 대해 단일 어댑터를 작성함으로써, 데이터 파이프라인 전반에서 어댑터를 원활하게 사용할 수 있습니다.
효율적인 모델 버전 관리를 위해, Dagster와 함께 파일 기반, Git 기반, 또는 데이터베이스 기반 버전 관리 시스템을 사용할 수 있습니다. 가장 간단한 형태로는, 스토리지 시스템의 파일 경로를 활용해 모델 버전을 저장하고, 이를 Dagster 플랫폼 내에서 자동으로 관리할 수 있습니다.
# 모델 모니터링 및 가시성 지원
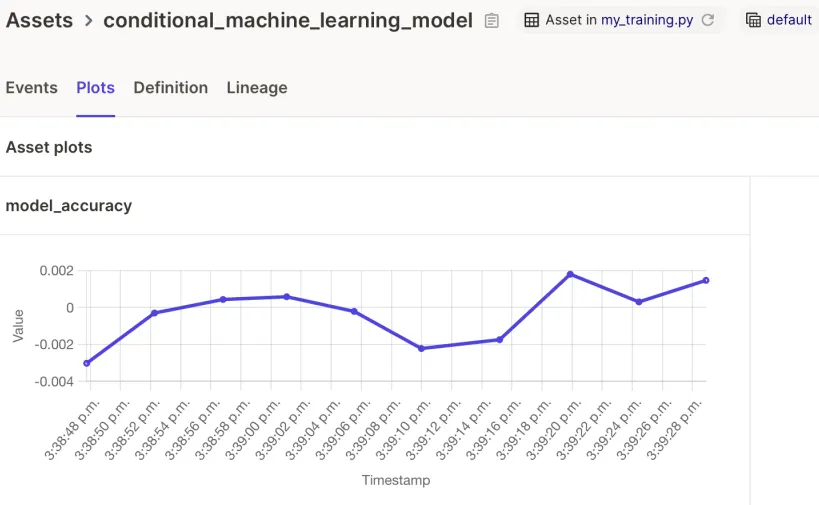
Dagster는 모델 모니터링과 시각화를 기본으로 지원합니다. 시간을 두고 모델 성능을 시각화함으로써, 개선이 필요한 부분과 최적화 가능성을 파악할 수 있습니다. 또한, Dagster를 사용하여 모델 성능에 대한 임계값을 설정하고, 성능이 해당 임계값 아래로 떨어질 때 모델을 자동으로 재학습할 수 있도록 설정할 수 있습니다.
# 환경별 품질 보장 및 배포

Dagster는 로컬과 프로덕션 환경 모두에서 데이터 파이프라인을 쉽게 테스트하고 디버깅할 수 있도록 해줍니다. 환경 설정을 개별적으로 구성함으로써, 개발자가 단계 전환 시 코드베이스를 변경할 필요가 없습니다. 이를 통해 개발 과정 전반에서 데이터 품질이 유지됩니다.
# 핵심 요약
결론적으로, Dagster는 DataOps 및 MLOps 구현에 다음과 같은 이점을 제공합니다:
- 복잡한 데이터 파이프라인 관리 개선
- 기존 기술 스택과의 원활한 통합
- 오래되거나 불필요한 자산 자동 식별
- 효율적인 데이터 전송을 위한 재사용 가능한 IO 매니저
- 향상된 데이터 품질을 위한 쉬운 디버깅 및 테스트
- 로컬과 프로덕션 환경에서의 효율적인 배포
강력한 기능과 사용의 용이성을 갖춘 Dagster는 데이터 엔지니어링 및 머신러닝 파이프라인 내에서 데이터 및 머신러닝 모델 운영을 가능하게 합니다.