# MLOps 03: Feast Feature Store — An In-depth Overview Experimentation and Application in Tabular data
MLOps 03: Feast Feature Store — An In-depth Overview Experimentation and Application in Tabular data (opens new window)를 읽고 번역한 내용입니다.
# 왜 Feature Store가 필요한가
예시) 한 데이터 과학 팀이 고객 이탈을 예측하는 머신러닝 모델을 구축하고 있다고 가정합니다. 그들은 데이터를 신중하게 수집하고 정리한 후, 이제 피처 엔지니어링에 착수할 준비가 되어 있습니다. 하지만 아래와 같은 문제를 마주합니다.
- 데이터 사일로와 중복: 데이터 과학자들은 필요한 피처들이 여러 데이터베이스와 노트북에 흩어져 있는 상황을 마주합니다. 학습과 서빙에 동일한 피처를 재현하는 작업은 오류/불일치가 발생하기 쉽습니다.
- 시간 낭비: 모델 개발과 실험에 집중해야 할 소중한 시간이 데이터 정제에 소모됩니다.
- 버전 관리의 어려움: 다양한 피처 버전이 여기저기 떠돌아다니며 혼란을 일으키고, 결국 모델 결함으로 이어질 수 있습니다.
이때 Feature Store가 등장하여 이러한 문제를 해결하고 머신러닝 워크플로우를 간소화하는 데 도움을 줍니다.
# 왜 Feast를 Feature Store로 선택하는가?
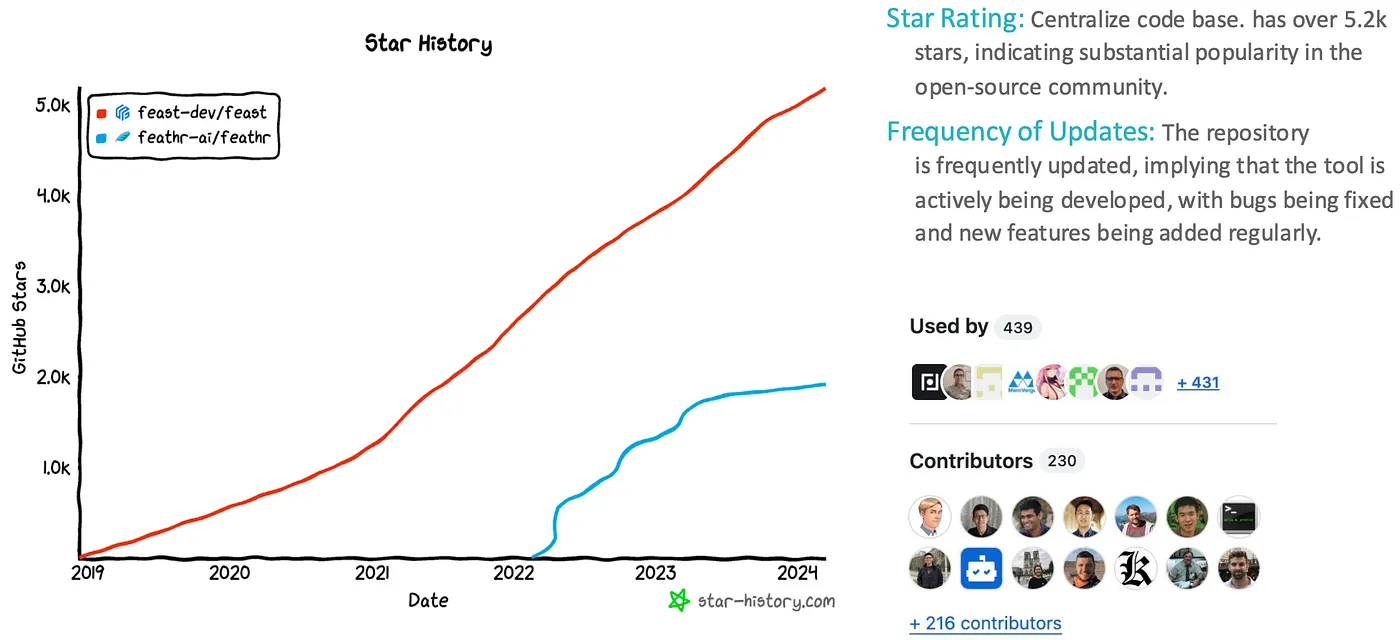 여러 Feature Store가 존재하지만, Feast는 뛰어난 기능을 조합해 제공합니다. 기존 인프라를 활용하고 데이터 일관성을 보장하며 데이터 누수를 방지하는 데 중점을 두어, 머신러닝 워크플로우를 최적화하고자 하는 조직에 강력한 선택지로 자리 잡고 있습니다.
여러 Feature Store가 존재하지만, Feast는 뛰어난 기능을 조합해 제공합니다. 기존 인프라를 활용하고 데이터 일관성을 보장하며 데이터 누수를 방지하는 데 중점을 두어, 머신러닝 워크플로우를 최적화하고자 하는 조직에 강력한 선택지로 자리 잡고 있습니다.
Feast는 오픈 소스 특성, 확장성, 그리고 활발한 커뮤니티 지원을 통해 피처 스토어 요구 사항을 충족시키는 강력한 후보로 떠오르고 있습니다. Feast의 문서와 리소스를 탐색하여 팀의 필요에 부합하는지 확인하고, 고성능 ML 모델 구축을 위해 팀을 지원해 보세요.
Feast가 돋보이는 이유는 다음과 같습니다:
- 팀과 프로젝트 간 피처를 공유하여 중복 작업을 줄입니다.
- 프로젝트 간 데이터 일관성을 제공합니다.
- 피처 엔지니어링과 모델 개발을 분리합니다 (데이터 과학자들이 선호합니다).
- 실시간으로 피처에 접근할 수 있습니다.
- ML 전문가들이 친숙한 기존 도구들과 통합을 지원합니다 (예: Airflow, Dagster, MLFlow, K8s).
# Feast를 사용하여 피처 저장 및 서빙하는 방법
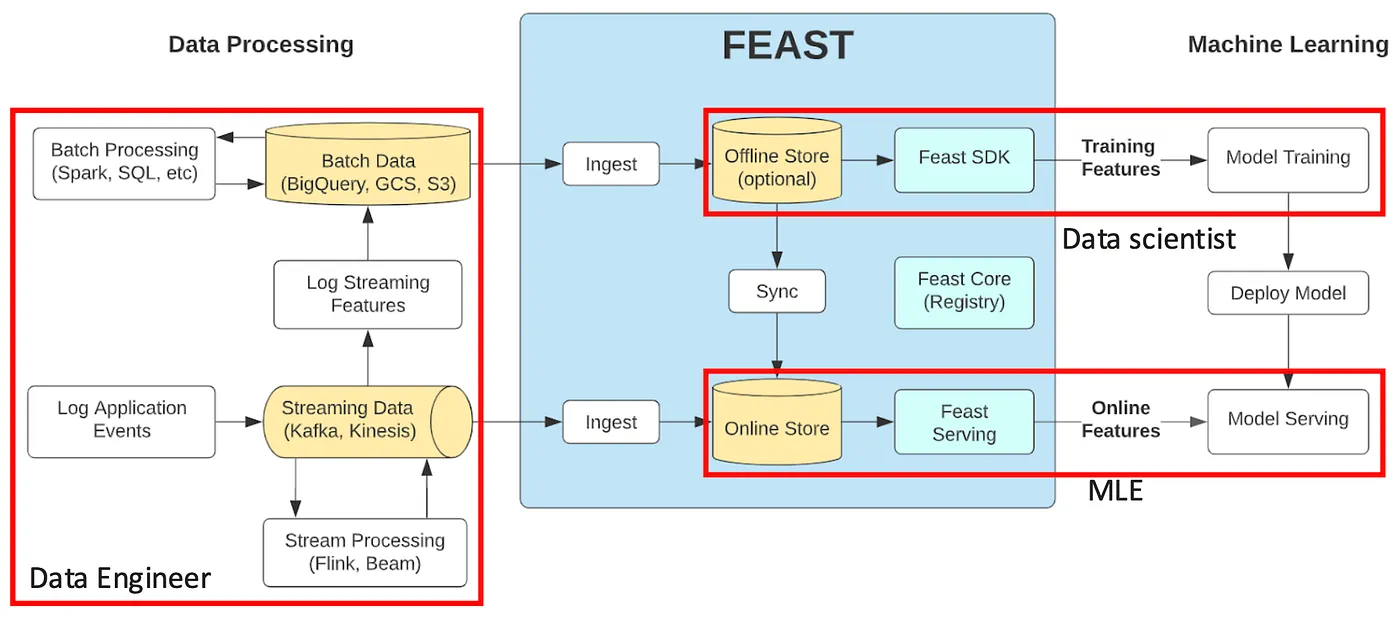 Source: MLOps Tools Part 5: BigQuery + Memorystore vs. FEAST for Feature Store (opens new window)
Source: MLOps Tools Part 5: BigQuery + Memorystore vs. FEAST for Feature Store (opens new window)
# Entity, Datasource, 그리고 FeatureView를 사용하여 피처 저장하기
- 피처 정의하기:
Feast는 피처 정의부터 시작합니다. 여기에는 피처 이름, 데이터 유형, 그리고 연결된 엔터티 키(예: 사용자 ID, 제품 ID)를 지정하는 과정이 포함됩니다. 데이터베이스, 데이터 웨어하우스, 실시간 스트리밍 서비스와 같은 다양한 데이터 소스를 위해 피처를 정의할 수 있습니다.
from feast import Entity
from feast.infra.offline_stores.contrib.spark_offline_store.spark_source import SparkSource
from feast import FeatureView, Field
# Entity
user = Entity(
name="user",
join_keys=["user_id"],
description="Entity to represent user for loan default prediction",
)
# Datasource
sparksource_user_loan = SparkSource(
path=os.path.join(get_feature_folder_path(), "loan_default_gen"),
file_format="parquet",
timestamp_field="txn_datetime",
name="user_loan",
)
# FeatureView
user_info_fv = FeatureView(
name="user_info",
entities=[user],
schema=[
Field(name="Age", dtype=Int64),
Field(name="Education", dtype=String),
Field(name="CreditScore", dtype=Int64),
Field(name="MonthsEmployed", dtype=Int64),
],
source=sparksource_user_loan,
description="Calculate overall transaction behaviors of customer",
)
- 피처 저장소 구축하기:
피처 저장소는 Feast의 설계도 역할을 합니다. 여기에는 피처 정의와 온라인 및 오프라인 저장을 위한 설정이 포함됩니다. Feast는 다양한 저장 옵션을 제공하여 필요에 따라 유연하게 선택할 수 있습니다.
각 Feast 배포에는 단일 피처 레지스트리가 있으며, 현재 Feast는 파일 기반 레지스트리만 지원하지만, 네 가지 백엔드를 지원합니다.
- Local: 개발 중 레지스트리를 저장하기 위한 로컬 백엔드
- S3: AWS에서 레지스트리를 중앙 집중식으로 저장하기 위한 백엔드
- GCS: GCP에서 레지스트리를 중앙 집중식으로 저장하기 위한 백엔드
- [Alpha] Azure: Azure Blob 스토리지에서 레지스트리를 중앙 집중식으로 저장하기 위한 백엔드
# https://docs.feast.dev/getting-started/architecture-and-components/registry
from feast import FeatureStore
# Simple: for local development
fs = FeatureStore("my_feature_repo/")
- 피처 생성하기 Feast는 “materialization” 프로세스를 사용하여 오프라인 저장소에 과거 피처 값을 채웁니다. 특정 시간 범위에 대해 피처 생성을 실행하여, 모델이 일관된 데이터 스냅샷으로 학습될 수 있도록 할 수 있습니다.
list_entities = [user]
list_datasources = [sparksource_user_loan]
list_feature_views = [user_info_fv]
fs.apply(
objects=[
*list_entities,
*list_datasources,
*list_feature_views,
],
)
실시간 추론을 위해 Feast는 낮은 지연 시간으로 접근할 수 있는 온라인 저장소를 활용합니다. 피처 생성은 최신 피처 값을 온라인 저장소에 채워 넣어, 모델이 예측 시 이를 사용할 수 있도록 합니다.
dt = datetime.now()
fs.materialize(start_date=dt - relativedelta(months=24), end_date=dt)
# get_historical_features, get_online_features를 사용하여 피처 서빙하기
- 훈련을 위한 피처 가져오기
Feast는 온라인 및 오프라인 저장소에서 피처를 가져오는 API를 제공합니다. 훈련 시, 이 API를 통해 오프라인 저장소에서 과거 데이터를 접근할 수 있습니다.
import pandas as pd
# Prepare entity dataframe with (user_id, event_timestamp) so that Feast can do Point-in-time joins
# https://docs.feast.dev/getting-started/concepts/point-in-time-joins
entity_df=pd.DataFrame(
[
['HlWpZydxscnmjGgeIPLi', pd.datetime(2023,1,2)],
['RckfsuJrhXFYAToUVlmy', pd.datetime(2024,1,9)],
['WJGbtTpKalFBqmMhcnPC', pd.datetime(2024,5,9)],
],
columns=['user_id','event_timestamp']
)
#
df_feature = fs.get_historical_features(
entity_df=entity_df,
features=[
'user_info:Age',
'user_info:Education',
'user_loan_ts:median_previous_income'
]
)
- 피처 서빙하기 (온라인 저장소):
마찬가지로, 실시간 예측을 위해 서빙 인프라가 온라인 저장소에서 최신 피처를 가져올 수 있습니다.
import pandas as pd
# Prepare entity dataframe with (user_id, event_timestamp) so that Feast can do Point-in-time joins
# https://docs.feast.dev/getting-started/concepts/point-in-time-joins
entity_df=pd.DataFrame(
[
['HlWpZydxscnmjGgeIPLi', pd.datetime(2023,1,2)],
['RckfsuJrhXFYAToUVlmy', pd.datetime(2024,1,9)],
['WJGbtTpKalFBqmMhcnPC', pd.datetime(2024,5,9)],
],
columns=['user_id','event_timestamp']
)
#
df_feature = fs.get_online_features(
entity_rows=[{'user_id': 'kyHoSmrOEWTzDRlpqBVQ'},
features=[
'user_info:Age',
'user_info:Education',
'user_loan_ts:median_previous_income'
]
)
다음으로, 각 시나리오 사용 사례를 간략하게 소개합니다.
# 시나리오 01: DS - 미리 계산된 피처를 기반으로 빠르게 실험하기
# 1. 피처 생성 및 등록 (스테이징)

- 1단계: 피처 구축
- 2단계: 피처를 저장소에 저장
- 3단계: 피처 스토어에 레지스트리 등록
# 2. 다른 훈련을 위한 피처 재사용
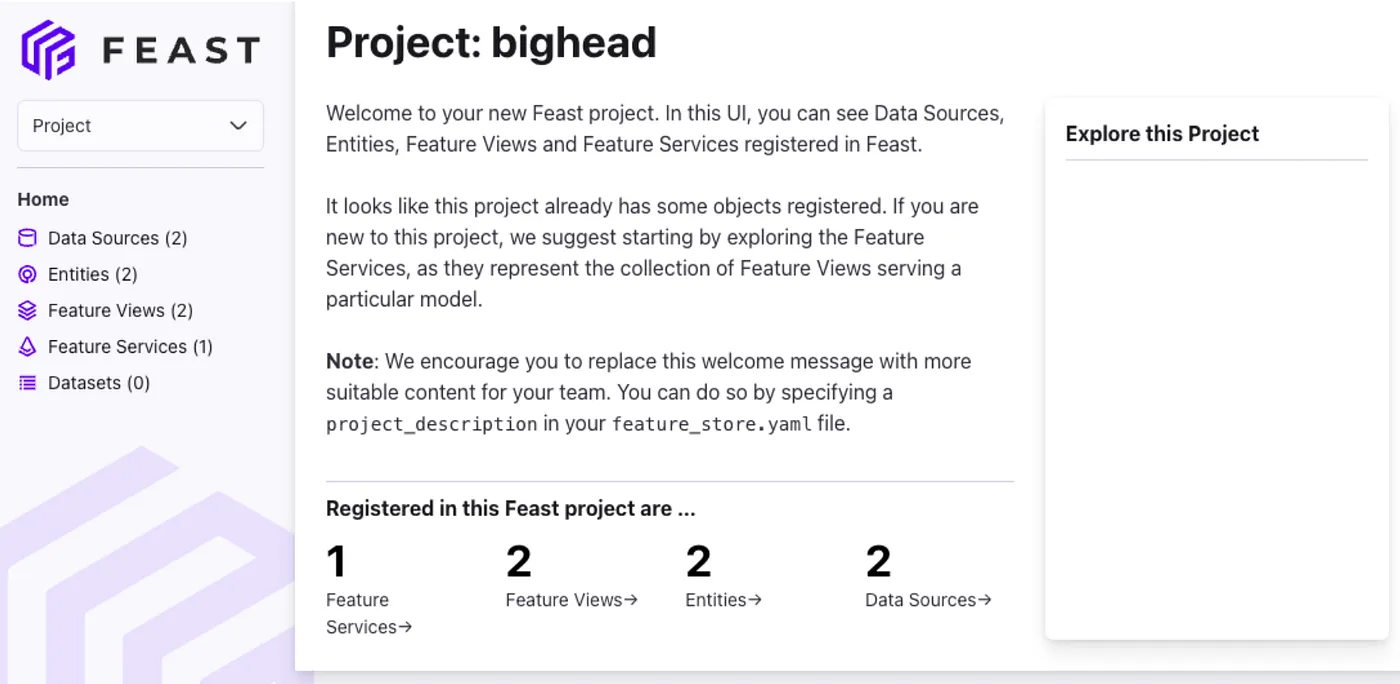
- 1단계: Feast UI를 탐색하여 고려할 피처 목록을 찾습니다.
- 2단계: get_historical_features, get_online_features를 사용하여 피처 세부 정보를 가져옵니다.
# 시나리오 02: DE — 데이터 파이프라인 통합 (프로덕션)
# CI/CD 파이프라인 준비 및 피처 자동 가져오기
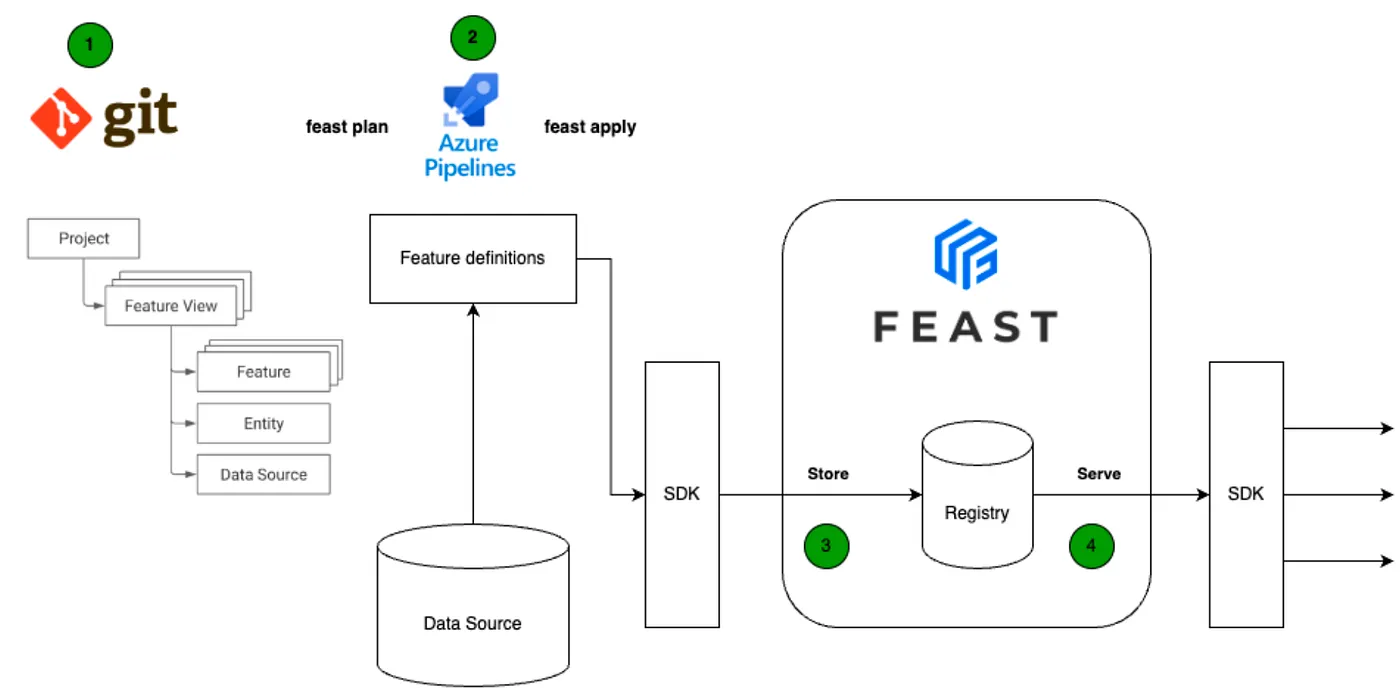

엔터티 목록 정의

FeatureView 목록 정의
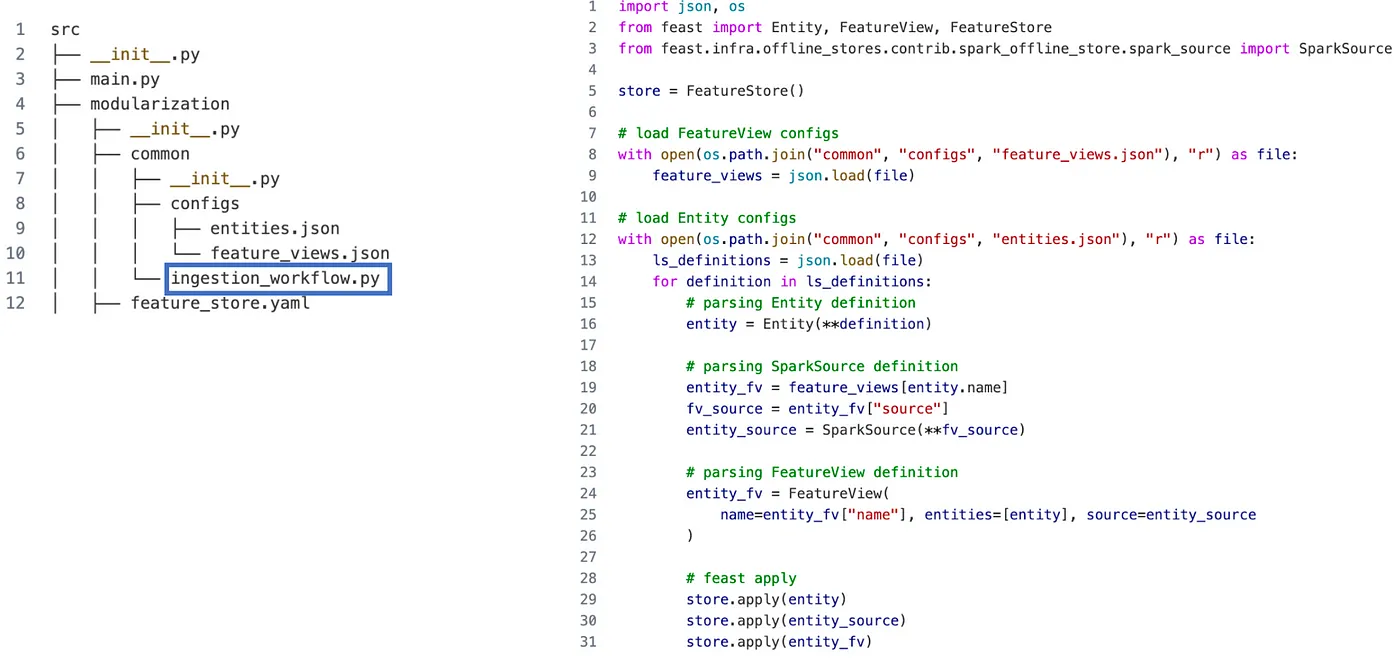
모든 엔터티와 피처를 레지스트리에 등록
# 시나리오 03: MLE — 온라인 API 추론 서빙
 Source: A State of Feast (opens new window)
Source: A State of Feast (opens new window)
@app.post("/predict_loan_default")
def predict_loan_default(request_loan_predict: Request) -> Response:
# 1. Load model and parse requests' info
xgb: XGBClassifier=ml_models['model']
feature_dict={}
user_id=request_loan_predict.user_id
feature_dict['loan_amount']=request_loan_predict.loan_amount
feature_dict['loan_term']=request_loan_predict.loan_term
feature_dict['dti_ratio']=request_loan_predict.dti_ratio
feature_dict['interest_rate']=request_loan_predict.interest_rate
# 2. Get pre-built features from Feature store
store:FeatureStore=ml_models['store']
fs_model=store.get_feature_service('user_xgb_v1')
features_from_store = store.get_online_features(
features=fs_model, entity_rows=[{'user_id':user_id}]
).to_dict()
# 3. Combine all features
list_feature=[]
for feature in xgb.feature_names_in_:
if feature not in feature_dict:
feature_dict[feature]=features_from_store[feature][0]
list_feature.append(feature_dict[feature])
# 4. Make model inference
score=xgb.predict_proba(np.array([list_feature]))[0][1]
# 5. Response results
response=Response(request=request_loan_predict,default_score=score)
return response
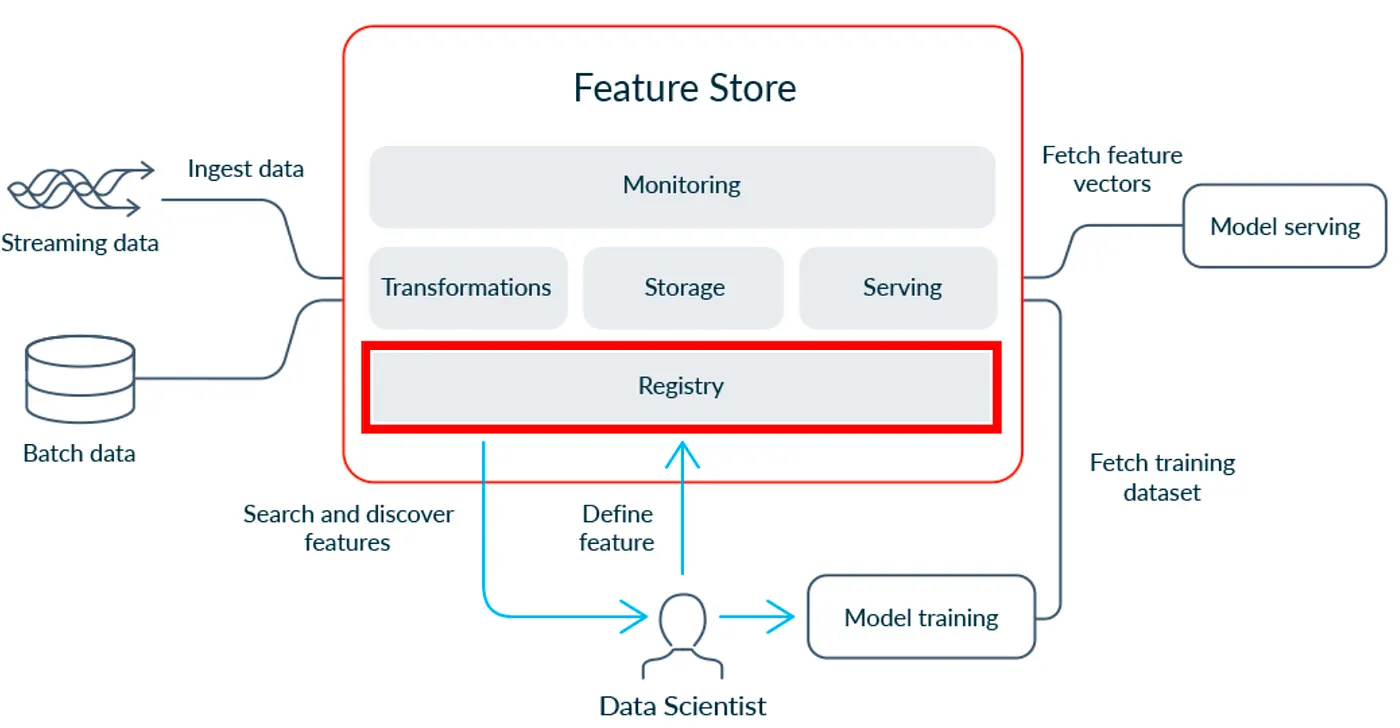
# 논의
# Future Directions:
- 벡터 데이터베이스 지원 확장: 추가 벡터 데이터베이스와의 호환성 추가를 탐색하여 더 다양한 사용자 요구와 선호를 충족시킵니다.
- 데이터 품질 모니터링 성숙화: 벡터화된 데이터 내의 잠재적인 문제를 식별하고 해결하는 강력한 기능을 제공하기 위해 데이터 품질 모니터링 기능 개발을 계속합니다.
- 텍스트 및 이미지 피처 통합: 텍스트 및 이미지 피처에 대한 워크플로우와의 원활한 통합을 탐색하여, 사용자가 이미지 검색이나 텍스트 유사도 분석과 같은 작업을 위해 VectorDB를 활용할 수 있도록 합니다.
# Strengths:
- 표준화되고 일관된 피처: 동일한 정의와 변환이 적용된 모델 간에 피처 사용을 보장합니다.
- 시계열 지원: 시간 지점의 정확성을 제공하여 금융 데이터나 거래 데이터에서 중요한 요소가 됩니다.
- 다른 도구와의 통합: Feast는 Airflow, Dagster, MLFlow, K8s와 같은 인기 있는 머신러닝 프레임워크와 잘 통합되며, 데이터 및 모델 관리 도구와도 호환됩니다.
- 온라인 및 오프라인 지원: 실시간 예측과 배치 예측을 돕고, 훈련과 예측을 위한 모든 피처 데이터를 관리하는 통합된 방법을 제공하여 모델 배포 및 서빙을 간소화합니다. 현재 Feast는 SnowFlake, BigQuery, PostgreSQL, MySQL, RedShift, Athena, DuckDB, Trino, Ibis, Redis, DynamoDB, Cassandra, HBase, Rockset, Hazelcast 등을 지원합니다.
- 데이터 버전 관리: 피처의 다양한 버전을 쉽게 관리하고 추적할 수 있습니다.
# Weaknesses:
- 복잡성: 간단한 프로젝트나 머신러닝을 시작하는 팀에게는 과도할 수 있습니다.
- 최소한의 UI: 피처 탐색 및 관리에 대한 최소한의 사용자 인터페이스 옵션을 제공합니다.
- 제한된 데이터베이스 지원: 현재 Feast는 Google BigQuery, Redshift, Snowflake, Spark, PostgreSQL과 같은 제한된 데이터베이스만 지원합니다.
- 문서 부족: 개선 중이지만, Feast의 문서는 특히 복잡한 배포나 고급 사용 사례에 대해 여전히 부족한 부분이 있습니다.