# Metrics Monitoring and Alerting system
Metrics Monitoring and Alerting system (opens new window) 을 읽고 번역하였습니다.
확장 가능한 메트릭 모니터링 시스템을 설계하여 시스템 상에서 관측 가능한 메트릭(metric)뿐만 아니라 비즈니스 요구에 따른 사용자 정의 메트릭도 수집할 수 있습니다.
시스템 메트릭 예시
- CPU 부하
- 메모리 사용량
- 디스크 사용량
- RPC 서비스의 초당 요청 수
- RPC 서비스 지연 시간
RPC는 원격 프로시저 호출(Remote Procedure Call)을 뜻하며, 프로세스 간 통신 기술 중 하나입니다. RPC를 이용하면, 별도의 원격 제어 코딩 없이 다른 주소 공간에서 함수나 프로시저를 실행할 수 있습니다. RPC의 주요 특징
- 서로 다른 프로세스 간에 원격 함수 호출을 허용
- 프로그래머는 함수가 실행 프로그램에 로컬 위치에 있든 원격 위치에 있든 동일한 코드를 사용할 수 있음
- API 간 통신을 위한 가장 간단하고 오래된 방법 중 하나
사용자 정의 메트릭 예시
- 지역(locale)별 사용자 수
- 엔드 투 엔드 메시지 전송 지연 시간: 채팅 메시지의 메시지 전송 시작 시간~수신자에게 전달된 시간
시스템은 메트릭을 기반으로 경고를 생성해야 합니다. 경고 예시
- RPC 오류 비율이 임계값을 초과할 경우 경고 생성
- 서버의 CPU 사용량이 임계값을 초과할 경우 경고 생성
- 로그인 재시도 횟수를 카운트하는 사용자 정의 메트릭이 제한을 초과할 경우 경고를 생성
이러한 경고는 이메일, 휴대폰 문자 메시지, PagerDuty, 또는 웹훅 HTTP 호출로 전송되어야 합니다.
참고: 이 설계에서는 모니터링 시스템이 수집한 데이터를 기반으로 경고를 설정하는 데 중점을 둡니다. 경고는 서버 로그나 액세스 로그를 기반으로 하지 않습니다.
# High level system design
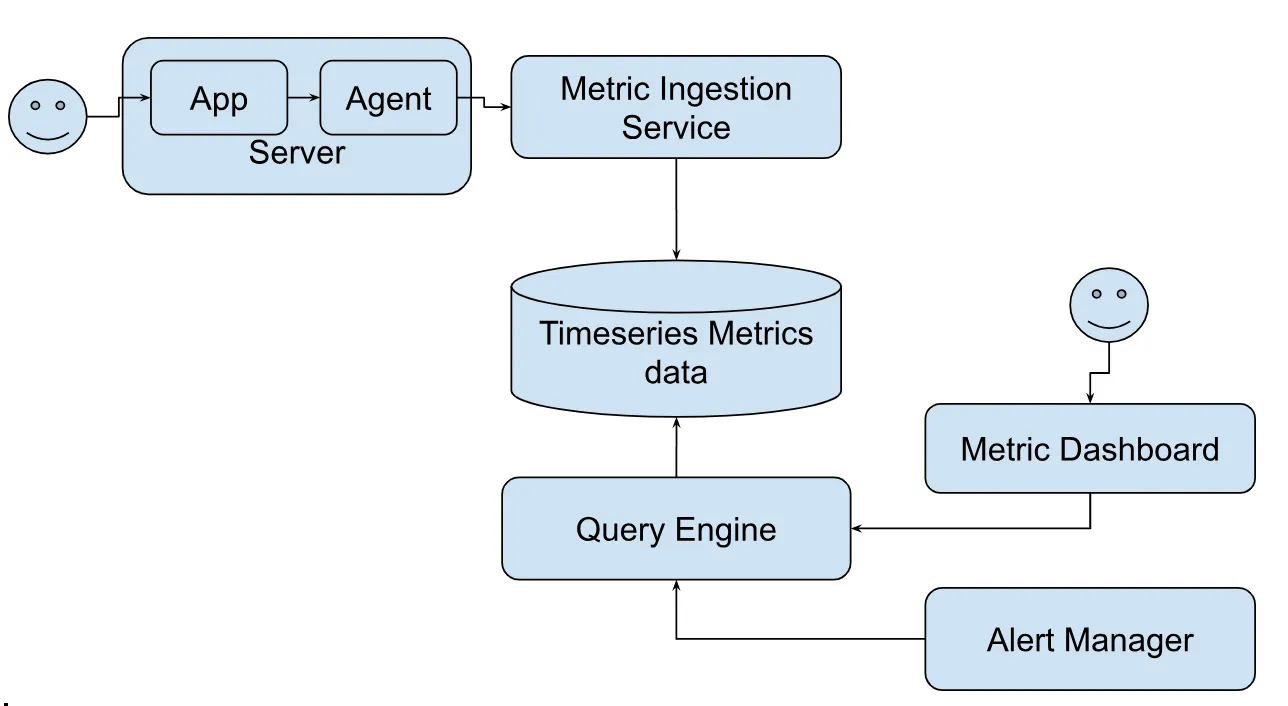 필요한 구성 요소
필요한 구성 요소
- 데이터 수집: 다양한 소스에서 메트릭 데이터를 수집
- 데이터 전송: 소스에서 메트릭 모니터링 시스템으로 데이터를 전송
- 데이터 저장: 메트릭 시계열 데이터를 정리하고 저장
- 쿼리 서비스: 메트릭 데이터를 쿼리
- 시각화: 실시간 및 과거 메트릭 데이터를 다양한 그래프와 차트로 시각화
- 경고: 데이터에 규칙을 실행하고 경고를 생성하여 다양한 통신 채널로 알림을 보냄
# Data collection and transmitting to monitoring system
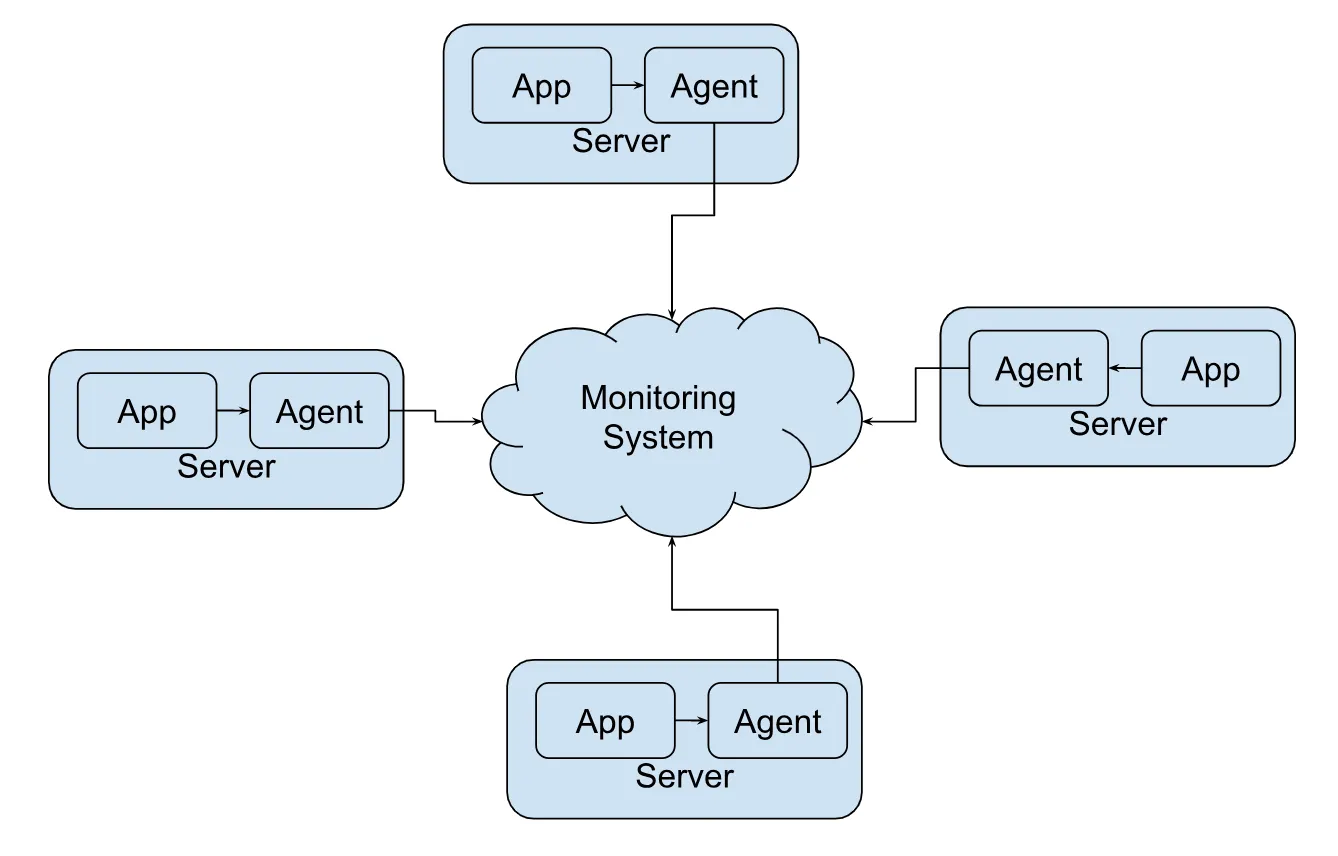
- 애플리케이션은 메트릭 데이터를 내보내도록 수정됩니다.
- 각 서버에 메트릭 에이전트를 설치하여 메트릭 데이터를 수신합니다.
- 에이전트는 로컬 버퍼를 유지하며, 버퍼가 가득 차면 UDP 프로토콜을 사용하여 이 데이터를 배치(batch) 형태로 모니터링 시스템에 전송합니다.
- TCP보다 UDP 프로토콜을 선호하는 이유는 지연 시간이 낮고 데이터 손실 위험이 허용 가능하기 때문입니다.
# Data model for storage
메트릭 데이터는 소스에서 특정 타임스탬프와 함께 생성되는 시계열 데이터입니다.
- 서버 메타데이터: server_user, job_name, machine_name, process_id 등 서버 관련 정보
- 메트릭 메타데이터: metric_name 및 기타 사용자 정의 태그(예: client_type, language 등)
- 메트릭 값: 메트릭의 시계열 값을 나타내며, 누적(cumulative) 또는 비누적(non-cumulative)일 수 있음
모든 메트릭은 자체 테이블에 저장됩니다. 각 행은 서버 메타데이터와 메트릭 태그의 특정 조합에 대한 데이터 스트림입니다.
/search/counter 메트릭의 스키마 예제:
ServerUser JobName MachineName ProcessId ClientType Language /search/counter
xxxx yyyy zzzz 1 Web EN t1:xx,t2:xxx,t3:xx
xxxx yyyy zzzz 1 iOS EN t1:xx,t2:xxx,t3:xx
xxxx yyyy zzzz 1 Android EN t1:xx,t2:xxx,t3:xx
애플리케이션이 특정 간격으로 값을 기록하기 때문에, 이 데이터는 서로 다른 타임스탬프에서 기록되는 데이터 스트림입니다.
/search/counter 데이터 스트림 예제:

- 각 행은 특정 타임스탬프에서 수집된 값을 포함한 데이터 스트림입니다.
- 이 예제에서 값은 증가하지만, 데이터 종류에 따라 값이 증가하지 않을 수도 있습니다.
# 데이터 스트림 타입
- Boolean
- Int64
- Double
- String
- Tuple
- Distribution
타입은 아래와 같이 다시 분류할 수 있습니다.
- 비누적(Non-cumulative): String 또는 Boolean은 항상 비누적입니다. 숫자(Number) 값도 비누적일 수 있음. 예: RPC 지연 시간(RPC latency).
- 누적(Cumulative): 프로세스의 수명 동안 값이 절대 감소하지 않는 메트릭입니다. 서버가 재시작되었을 때만 초기화. 예: 함수가 에러를 발생시킨 횟수를 카운트하는 메트릭은 프로세스 수명 동안 감소하지 않습니다.
# 분포 데이터 타입(Distribution Data Type)
- 분포(Distribution) 데이터 타입은 메트릭 시스템에 고유한 데이터 타입입니다.
- 특정 값을 여러 범위(버킷)로 나누는 히스토그램을 포함
- 각 버킷은 합계(sum), 평균(mean), 개수(count), 표준편차(standard deviation) 등의 통계값을 요약하여 저장
- 디버깅 목적으로 버킷별로 예제 값을 포함할 수도 있습니다.
분포 데이터 타입에서 누적(Cumulative)과 비누적(Non-Cumulative)의 차이
Streams:(00:01,0.3)(00.01,0.5)(00.01,1.8)(00:02,0.3)(00:02,0.5)(00:02,2.7)
Non Cumulative distributions:
Bucket T0 T0+1m T0+2m
[0,1) 0 2 2
[1,2) 0 1 0
[2,4) 0 0 1
Cumulative distributions:
Bucket T0 T0+1m T0+2m
[0,1) 0 2 4
[1,2) 0 1 1
[2,4) 0 0 1
# Data storage system
메트릭 데이터는 스키마 기반 데이터이면서 시계열 데이터입니다. 경고 시스템은 메트릭 저장소에 의존하기 때문에, 저장 시스템은 빠르고 신뢰할 수 있어야 합니다. 따라서 데이터를 디스크에 기록하는 대신 인메모리(in-memory) 저장소를 사용하는 것이 더 적합합니다. 데이터 복구를 위해 디스크에 기록하는 기능은 포함합니다. 일부 데이터를 잃어도 괜찮으므로 복구 로그를 쓸 때 확인(acknowledge)을 기다릴 필요는 없습니다.
# Intra zone setup
고도로 확장 가능한 시스템은 지리적으로 분산된 다수의 존에 설치되어야 합니다. (사용자 지원, 처리량 향상, 신뢰성 향상을 위한 것). 각 존에 독립적인 지역 단위(local unit)로 배포되어야 합니다. 로컬 단위는 해당 존에서 생성된 모든 메트릭 데이터를 저장합니다. 이는 데이터 삽입 확산(ingestion fanout)을 크게 줄입니다.
쿼리 실행 시 모든 가용한 존에서 데이터를 검색한 뒤 단일 출력(single output)으로 응답해야 합니다. 이러한 구조는 일부 존의 유닛이 실패해도 메트릭 데이터 생성이 중단되지 않도록 합니다.
Ingestion fanout은 데이터 처리 또는 전송 과정에서 단일 데이터 소스로부터 여러 목적지(destination) 또는 처리 경로로 데이터를 동시에 분배하는 패턴을 말합니다. 이 패턴은 데이터를 병렬적으로 전송하거나 처리하여 성능을 최적화하고 확장성을 높이는 데 사용됩니다.
- 데이터 복제: 원본 데이터를 여러 목적지로 동시에 전송합니다.
- 병렬 처리: 데이터를 다양한 처리 경로에서 동시에 처리할 수 있습니다.
- 유연성: 여러 애플리케이션이나 서비스가 동일한 데이터를 필요로 할 때 효율적으로 활용할 수 있습니다.
# Aggregation using bucket and admission window
Storage layer는 sliding admission window을 유지합니다. 버킷의 종료 시간이 admission window에서 벗어나면 해당 버킷은 확정(finalized)됩니다. 집계된 데이터 포인트는 인메모리 저장소와 복구 로그에 기록됩니다. 시각 오차(clock skew)를 처리하기 위해 TrueTime을 사용하여 deltas, buckets, admission window.에 타임스탬프를 부여할 수 있습니다.
# Query Engine
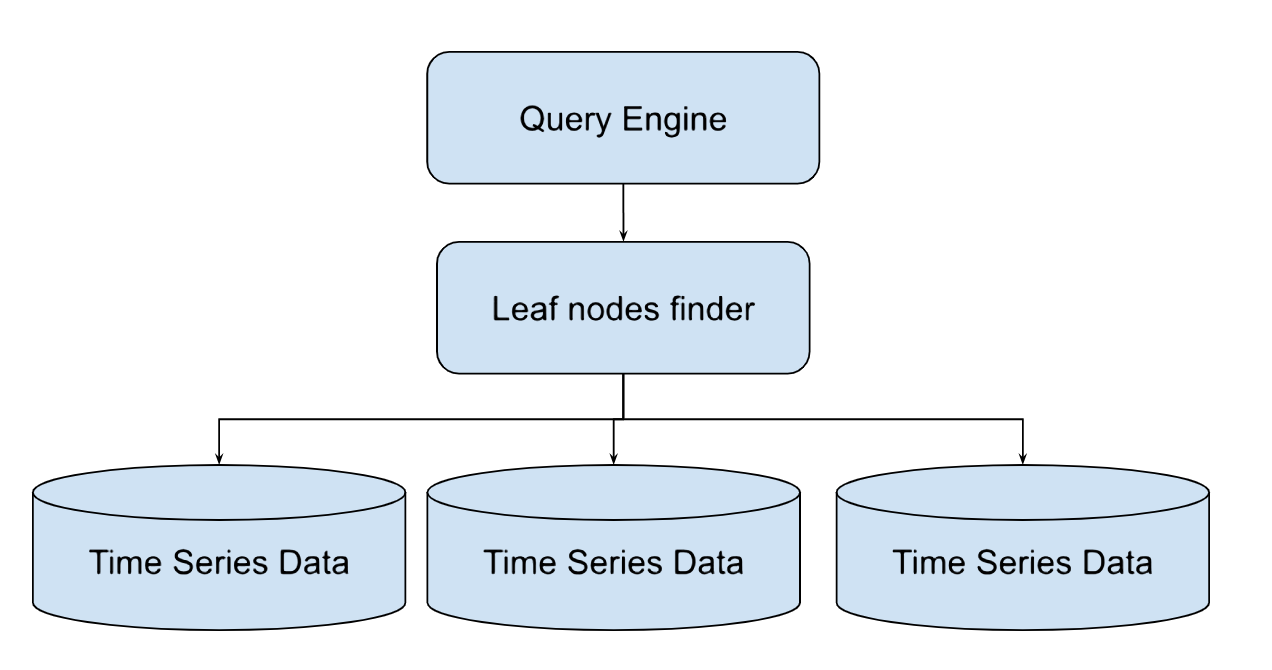 메트릭 데이터를 쿼리하기 위해 쿼리 엔진을 구축해야 합니다. 쿼리 엔진은 시계열 데이터베이스를 읽고 경고 또는 시각화에 필요한 데이터를 반환합니다. 데이터는 여러 노드와 존에 걸쳐 분산 저장되므로, 각 쿼리는 리프 노드 탐색기(leaf nodes finder)를 통해 리프 노드에서 실행됩니다.
메트릭 데이터를 쿼리하기 위해 쿼리 엔진을 구축해야 합니다. 쿼리 엔진은 시계열 데이터베이스를 읽고 경고 또는 시각화에 필요한 데이터를 반환합니다. 데이터는 여러 노드와 존에 걸쳐 분산 저장되므로, 각 쿼리는 리프 노드 탐색기(leaf nodes finder)를 통해 리프 노드에서 실행됩니다.
SQL 스타일 쿼리 예제:
{
fetch ComputeTask::/rpc/server/latency
| fitler user=="app-user"
| align delta(1h)
; fetch ComputeTask::/build/lable
| filter user=="app-user" && job="prod-00-us"
} | join
| group_by [label], aggregate(latency)
쿼리 출력 예시:

# Sharding
레키시코그래픽 샤딩(lexicographic sharding)은 특정 스키마와 관련된 키 열을 기반으로 존 내 데이터를 샤딩합니다.
예를 들어 ComputeTask::sql-dba::db.server::aa::0876는 데이터베이스 서버의 프로세스를 나타냅니다. 이러한 타겟 범위(target range)를 사용하여 쿼리 내 인접 타겟 간 효율적인 집계와 리프 노드 간 부하 분산(load balancing)을 수행할 수 있습니다.
# 경고 시스템(Alerting System)
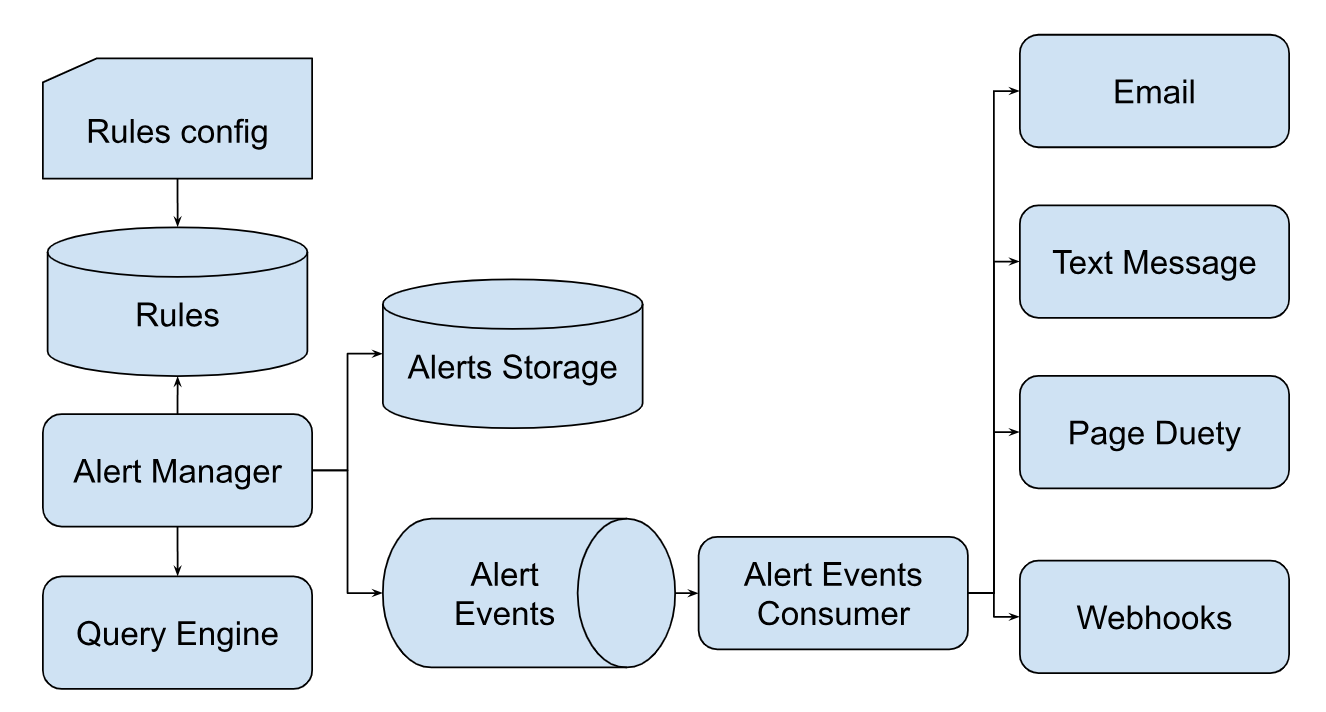
경고 시스템은 주요 네 가지 구성 요소로 이루어져 있습니다:
- 규칙 구성(Rules Config): 메트릭 평가를 기반으로 경고를 트리거하는 사전 정의된 규칙을 포함합니다.
- 경고 관리자(Alert Manager): 규칙을 주기적으로 실행하며 이상이 감지되면 이벤트를 큐(Queue)에 게시해 고객에게 알립니다.
- 경고 소비자(Alert Consumer): 큐에서 이벤트를 수신하고, 사용 가능한 통신 채널을 통해 수신자에게 전달합니다.
- 통신 채널(Communication Channel): 이메일, 문자 메시지, PageDuety, Webhooks 등이 포함됩니다.
# 시각화 시스템(Visualization System)

시각화 시스템은 쿼리 엔진 위에 구축되며, 다음과 같은 기능을 제공합니다:
- 특정 메트릭 데이터를 로드합니다.
- 시간 범위 및 사용자 정의 태그를 기준으로 필터링합니다.
- 메트릭 데이터를 그래프로 시각화합니다.
# Reference
제안된 시스템 설계는 Google의 Monarch 시계열 데이터베이스를 기반으로 합니다. 메트릭 및 경고 시스템에 대해 더 깊이 이해하고 싶다면 다음 논문을 참고하세요. Monarch: Google’s Planet-Scale In-Memory (opens new window)